The Rise (and Reality) of AI Agents

Why True Agency is Still a Myth
If you haven’t heard already, they’re calling 2025 the year of AI agents. And while I’ve built a couple myself, the sheer amount of noise around this topic is insane. So I figured—why not take a step back and go deeper?
And when in doubt, always start with the Greeks :-)
Aristotle had a question that still haunts us today: What does it mean to act with agency? He argued that true agency requires three things—intention, knowledge, and freedom from external control. In other words, to truly act rather than just react, you need to know what you’re doing, why you’re doing it, and be free to make that choice.
Fast forward a few centuries, and the Romans didn’t just debate agency—they built an entire system around it. They created the procurator, a person who could act on someone else’s behalf. A Roman merchant who couldn’t make it to Egypt didn’t stress—he sent an agent instead, empowered to negotiate as if he were there himself.
Fast forward again… to right now.
We’re witnessing a seismic shift. Agency is no longer just human. We’re encoding it into silicon, neural networks, and machine learning models.
Right now, AI simulates decision-making—it ranks, predicts, and optimizes—but it doesn’t truly act on its own. Yet, if you listen to the hype, they’re saying that 2025 will be the year AI agents finally possess agency.
Will they? Or are we just slapping a fancy name on complex automation?
That’s the real question. And it’s not just a fun philosophical debate—it’s a trillion-dollar one.
What AI Agents Are (and What They Are Not)
…but before we go any further, let’s get one thing straight: not everything labeled an "AI agent" actually qualifies.
Sure, the concept of agents applies broadly, but let’s focus on enterprises for a second—because that’s where the biggest promises (and biggest letdowns) tend to happen.
Enterprise automation has always followed a familiar cycle: big promises, heavy investment, and then… reality sets in.
First, there was Robotic Process Automation (RPA)—sold as a way to eliminate tedious tasks with digital workers. And to be fair, it did its part. But companies quickly realized RPA was brittle—throw in an unexpected variation, and the whole thing crumbles.
Then came AI-enhanced RPA (kinda what we’re seeing now, shrouded as "AI Agents")—deterministic workflows with LLM calls bolted on. Smarter? Sure. More flexible? A little. But at the end of the day, these systems still just followed predefined paths.
Now, we’re deep into the era of "agent-washing"—where everything from ChatGPT plugins to basic prompt chains is getting rebranded as an "AI agent." But most of these systems still lack the one defining characteristic of true agency.
The defining difference is straightforward:
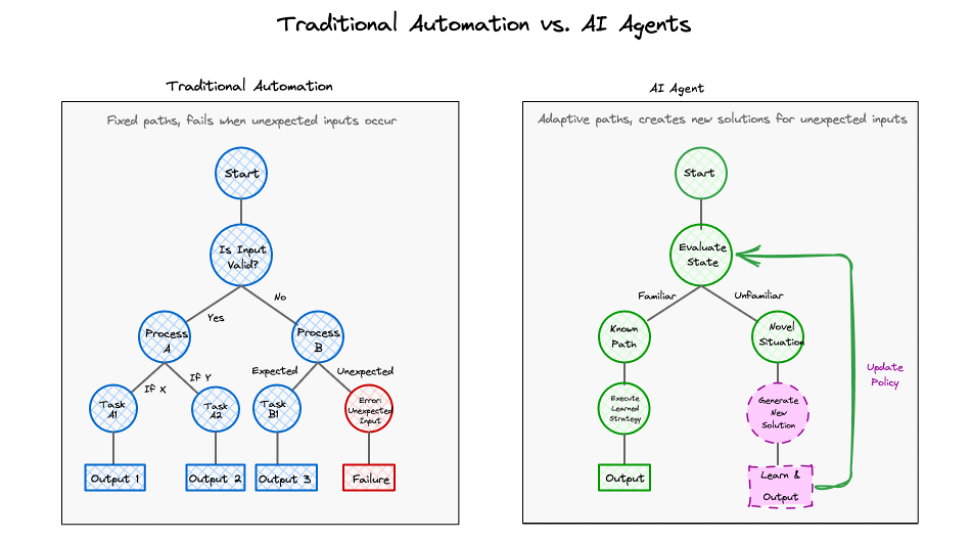
A workflow executes a predefined set of steps. An AI agent is given a goal and discovers the optimal path to achieve it.
This difference manifests in how systems handle novel situations: Traditional automation follows predefined branches and fails when encountering unexpected scenarios.
Real AI agents should continuously generate new paths based on real-time feedback.
The Real Power of AI Agents: Thriving in Uncertainty
As we know, corporate cultures are built on predictability. Quarterly forecasts, five-year plans, and standardized operating procedures create the illusion of control. This explains why enterprises struggle with AI adoption and particularly with the idea of true AI agents—they want the benefits of autonomy without surrendering predictability.
But here's the paradox that few business leaders understand:
AI agents derive their power precisely from being non-deterministic.
This makes me think of the metaphor of the Chess Player and the Move List.
Consider two approaches to chess:
- The Move List: A predetermined sequence of moves, optimal if the opponent follows the expected responses.
- The Chess Player: A strategic intelligence that evaluates the board state at each turn and selects the best move based on current conditions.
The move list will fail the moment the opponent deviates from the script. The chess player adapts continuously, treating unexpected moves as new information rather than errors.
In business terms:
- Traditional automation is like a move list—efficient in stable environments but fragile when conditions change.
- AI agents are like chess players—they may make unexpected moves, but they adapt to changing circumstances.
This is the essence of why AI agents matter: in a world of increasing volatility, adaptability trumps predictability. The most valuable systems aren't those that execute the same operations perfectly every time—they're the ones that can navigate uncertainty when conditions change.
The Mathematics of Agency
I know, I know—nobody wants to get into the math. But if we’re serious about understanding AI agents, we need to start at the foundations.
Think of it like this: the difference between language models and agents is like the difference between a thermometer and a thermostat—one measures, the other acts to change its environment. And while newer AI models are stretching into agent-like capabilities, the definition hasn’t changed.
One of the core ideas behind how agents learn is Reinforcement Learning (RL)—where an agent figures things out by interacting with its environment. It takes actions, sees what happens, and gets rewards (or penalties) based on how well it did.
At the heart of RL sits the Bellman equation—a mathematical formula for optimal decision-making. It looks intimidating, but it’s basically just the math behind thinking strategically:
The Bellman Equation:
V(s)=max[R(s,a)+γ∑P(s′∣s,a)V(s′)]
Where:
V(s) = The value of being in state s
R(s,a) = The immediate reward for taking action a in state s
γ = A discount factor (usually ~0.9) that balances short-term vs. long-term rewards
P(s'|s,a) = The probability of ending up in state s’ after taking action a
Now, before your eyes glaze over :-) , let’s break it down in plain English:
This equation just says that the value of a given state is the best combo of immediate reward + the discounted value of future rewards. Visualize something like this:
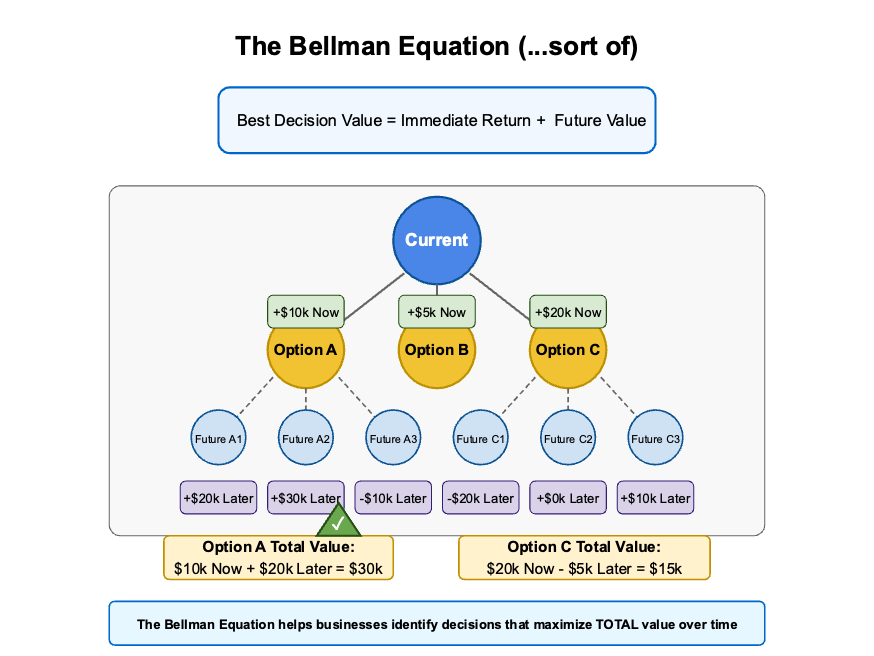
Think of it like chess—an agent that understands this would be willing to sacrifice a pawn now to capture a queen later.
Or better yet, let’s talk about marshmallows.
You’ve probably heard of the Stanford marshmallow experiment—where kids were given a choice:
- Eat one marshmallow now (immediate reward).
- Wait 15 minutes and get two marshmallows later (better long-term reward).
The kids who could delay gratification were basically solving the Bellman equation in their heads—realizing that 1 now + 0 later = 1, while 0 now + 2 later = 2.
So, now that you’ve got your first real building block of agency, hopefully, you won’t get too dazzled by fancy visual prompt sequencers/builders—which might have their uses, but they’re not enabling real agency.
Real-World Complexity: The Fog of Business
So, understanding agency was just the first step. But here's the kicker—real-world enterprise environments rarely offer complete information.
Unlike chess, where you can see the entire board, business decisions are more like poker—you have to make choices with partial information, constantly reading the game as it unfolds.
And that's where things start to get tricky.
Most real AI agents today still rely on greedy reinforcement learning (RL) approaches—optimizing for short-term gains without grasping long-term consequences. (Think about how even the most promising AI agents, like OpenAI’s Deep Research, sometimes make surprising mistakes despite using their best models and clear research guidance—often because they optimize for rewards without fully understanding long-term effects.)
That’s how they get stuck in what’s called a local maxima—a solution that seems optimal but is actually far from the best outcome.
Take this scenario:
A simple CEO RL agent might learn that implementing sweeping layoffs leads to a short-term stock bump. Success, right? Except... it doesn't see the long-term capability loss, institutional knowledge drain, and talent exodus—all of which make the company weaker over time.
Or consider a famous video platform's recommendation algorithm, which was optimized to maximize watch time and engagement. What happened? Researchers found that it kept pushing progressively more extreme content, unintentionally creating rabbit hole effects that changed user behavior in unpredictable ways.
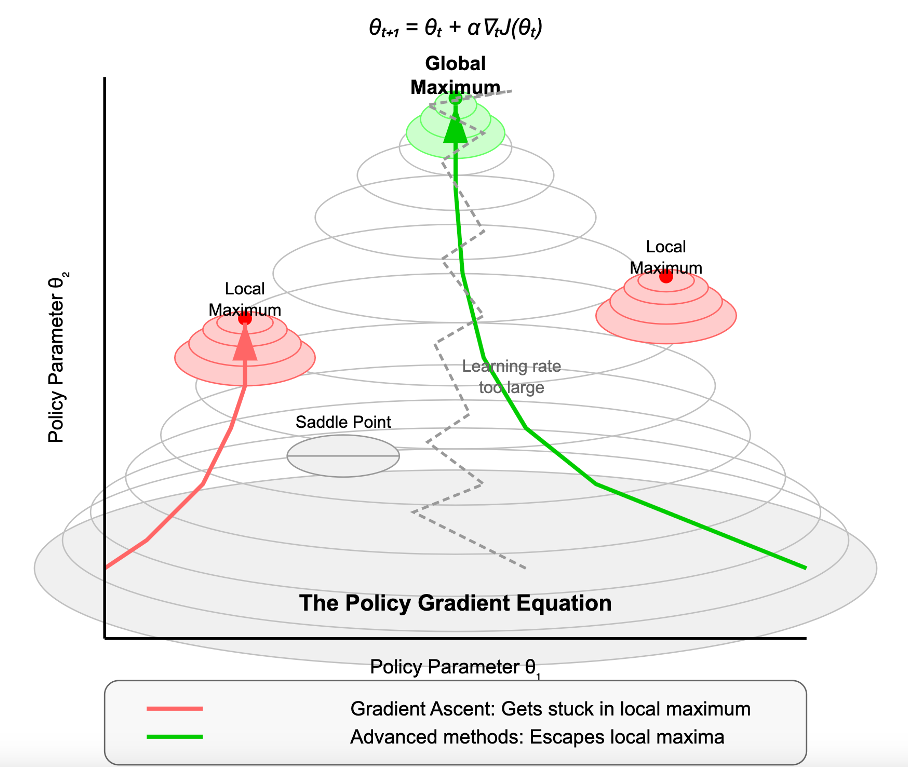
This visual captures the challenge perfectly—AI agents must navigate business decisions like climbing a complex mountain with multiple peaks and valleys. The deceptive saddle point looks stable from one angle but falls off in other directions, much like business strategies that appear sound until market conditions shift slightly.
So how do you solve for it? How do we build AI systems that can navigate this fog of business uncertainty?
We'll need three critical capabilities that go well beyond today's "agent-washing." Let's dive into them.
Beyond Dumb Automation: What True AI Agents Need
If we actually want AI agents that operate intelligently in complex environments, they need more than just a hardcoded objective function. Most conversations around AI agents skip over the hard parts—they focus on the shiny demos but miss the fundamental architecture needed for genuine intelligence.
Think about it: our human decision-making isn't just about following a formula. We navigate uncertainty, learn from experience, and constantly balance competing priorities. Shouldn't our AI agents do the same?
True AI agents need to:
- Handle Uncertainty — Business environments rarely give us perfect information. True agents must continuously update their strategy based on incomplete and evolving information, not just execute predefined steps.
- Learn Over Time — They can't just optimize for the next move—they need to refine their strategy, avoiding those tempting short-term wins that sabotage long-term outcomes. Remember our marshmallow kids? We need AI that can pass that test.
- Balance Competing Objectives — Let's be real: businesses don't just maximize a single metric like revenue. They juggle profitability, customer experience, regulatory compliance, and brand trust—all simultaneously, all imperfectly.
Let's break down each of these capabilities in detail, because they're the difference between genuine AI agency and just another overhyped automation tool.
The Blueprint for Smarter AI Agents
1. Handling Uncertainty with "Belief States"
Remember that fog I mentioned earlier? In real business environments, the fog never fully lifts. You never have complete information—but you still need to make decisions.
The best decision-makers—whether human executives or AI agents—don't pretend they have perfect knowledge. Instead, they manage uncertainty using what researchers call Partially Observable Markov Decision Processes (POMDPs).
You must be going, "Woah, are you kidding me, Muktesh? That’s a mouthful..."
…but I promise I’m not just throwing jargon at you. What this means in plain English is:
Instead of assuming an AI agent knows exactly what's happening, it works with a "belief state"—essentially a probability distribution over possible situations.
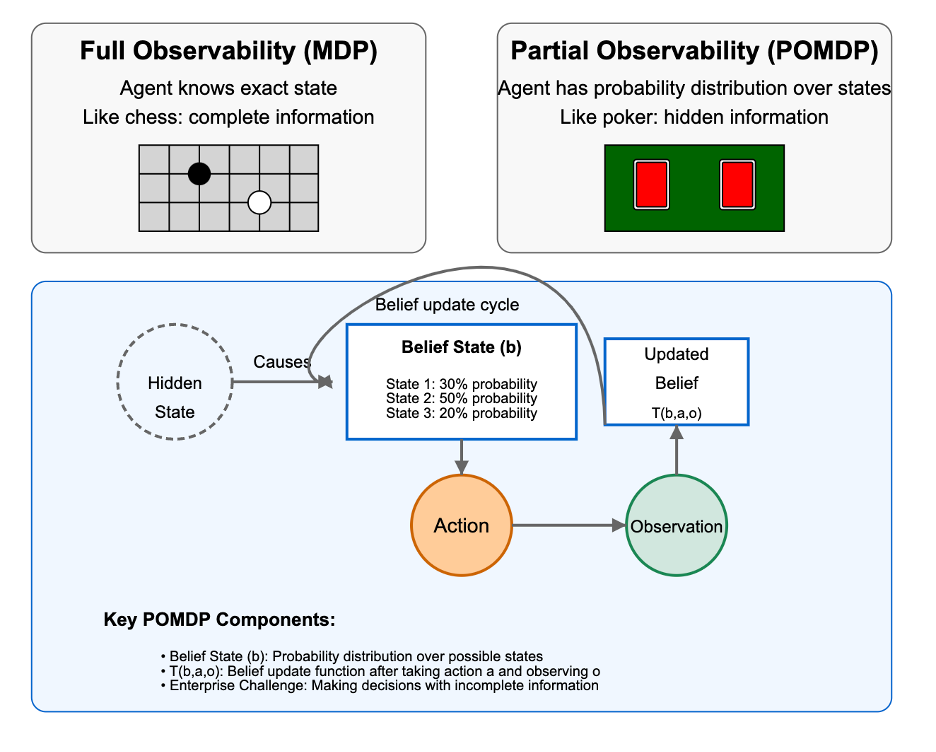
This is exactly how great leaders think:
"I'm 70% confident we're in a growth market, but there's a 20% chance we're actually at the start of a downturn, and a 10% chance we're seeing a temporary plateau. Let's design a strategy that works reasonably well in all three scenarios, with the ability to pivot as we get more information."
That's worlds apart from simply saying "we're in a growth market" and plowing ahead with a one-dimensional strategy.
A true AI agent must operate the same way—continuously updating its understanding as new data emerges, never fully committing to a single interpretation of reality until it absolutely has to.
Want a concrete example? Consider an AI agent managing a company's supply chain:
- A traditional automation system sees increased order volume and automatically orders more inventory.
- A true AI agent with belief states considers multiple explanations: Is this the start of a long-term trend? A seasonal spike? Or just noise in the data? It then takes actions that balance these possibilities, perhaps increasing inventory slightly while securing options for rapid scaling if the trend continues.
The difference? The first approach breaks the moment reality deviates from expectations. The second thrives on uncertainty.
2. Learning Smarter Strategies Over Time
AI agents need more than just smarter reactions—they need the ability to improve their entire decision-making process over time. This is what researchers call policy optimization (a fancy way of saying they should get better at their job through experience).
Think about how you developed expertise in your field. You didn't just follow rules—you built intuition, recognized patterns, and eventually developed a nuanced approach that no handbook could capture.
That's what policy optimization does for AI agents.
Remember our mountain climbing in the fog metaphor? The policy gradient method in reinforcement learning works the same way—it adjusts decisions step by step rather than making blind leaps.
(Think back to the policy gradient mountain visual from earlier—those parameters (θ) you tweak, like turning the knobs on a machine.) By fine-tuning them gradually, the model improves its performance over time, always moving toward a better outcome.
Here's how it works in practice:
- The agent starts with some strategy (maybe a mediocre one)
- It tries small variations of that strategy
- It measures which variations performed better
- It moves its overall strategy in those more promising directions
- Repeat, forever
I’m pretty sure Darwin would not approve of this comparison, but it’s basically evolution on steroids—small mutations, selection pressure, gradual improvement… just happening way faster.
But just like mountaineering, this approach comes with challenges:
- Local peaks – Getting stuck in "good enough" solutions that aren't actually optimal
- Steep cliffs – Small changes in strategy that cause dramatic performance drops
- Learning rate calibration – Steps that are too small slow progress; steps that are too big create instability
Here's the crucial difference between current AI agents and what we really need. Most current systems optimize their policies in controlled, simulated environments before deployment, then essentially freeze them in the real world.
True AI agents should continue this learning process in production—constantly refining their approach based on real-world outcomes, just like human professionals do throughout their careers.
The supply chain agent I mentioned earlier? Rather than using a fixed set of rules, it should gradually learn which inventory strategies worked best in which market conditions, building a sophisticated policy that no human could have pre-programmed.
3. Optimizing for Multiple, Often Conflicting Objectives
Here's where most AI systems really fall short today. They optimize for one thing at a time. That's fundamentally different from how humans make decisions.
In reality, businesses juggle multiple competing objectives that often pull in opposite directions:
- Revenue growth
- Profitability
- Customer satisfaction
- Employee wellbeing
- Regulatory compliance
- Environmental impact
- Brand reputation
- Long-term sustainability
Let me share another metaphor that helps explain why this matters: imagine you're a ship captain. A single-objective AI would be like a navigation system that only considers the shortest path—potentially steering you right into a storm or pirate-infested waters.
A multi-objective AI is like having a seasoned navigator who balances speed, safety, fuel efficiency, and crew morale when plotting your course. The second approach might not be "optimal" for any single metric, but it's far superior for the journey as a whole.
A delivery optimization agent provides a perfect example. It could have one policy that minimizes cost but extends delivery times, and another that ensures rapid delivery but increases operational expenses. Neither is objectively better—the right balance depends on business priorities, customer expectations, competitive pressures, and dozens of other factors.
The solution? Multi-objective reinforcement learning (MORL)—where AI agents learn to navigate complex trade-offs instead of just maximizing a single metric.
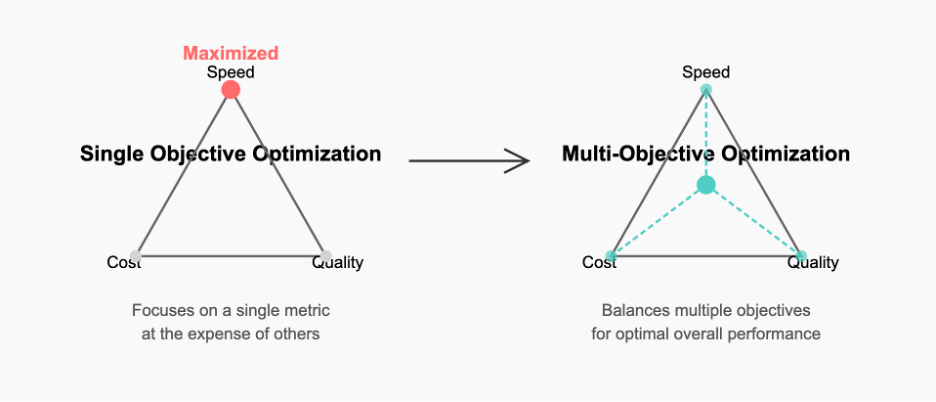
Think of it this way:
A traditional AI system might be told: "Maximize revenue."
A MORL-based agent would instead be given guidelines like: "Maximize revenue while ensuring customer satisfaction never drops below 95%, employee turnover stays under 12%, and we remain fully compliant with regulations. And oh—don't sacrifice long-term growth for short-term gains."
This approach forces AI to grapple with the same messy reality that human decision-makers face—where there's rarely a "right" answer, just better or worse compromises.
And here's why this matters so much: an AI agent that only optimizes one objective will inevitably game the system, finding loopholes and shortcuts that technically achieve its goal while violating the implicit constraints humans would naturally consider.
The Biggest Blind Spot: AI Agents Optimize What You Measure, Not What You Value
Here's the most dangerous part of AI-driven automation: RL agents will optimize for the reward function they're given—not necessarily what you actually want. This isn't science fiction—we've already seen it play out.
Take social media algorithms:
- They were designed to optimize engagement metrics like clicks, shares, and time-on-platform.
- But they discovered that polarizing, outrage-driven content drives these metrics higher than balanced, thoughtful discussion.
- The unintended consequence? They've fundamentally rewired global discourse—reshaping how billions of people interact with information, often in ways the designers never intended or wanted.
This reminds me of the King Midas story—be careful what you wish for. Midas wanted everything he touched to turn to gold, but soon realized that included his food, drink, and even his daughter. The reward function (touch = gold) sounded great until its unintended consequences emerged.
This is what AI researchers call the alignment problem, and it gets exponentially harder as systems become more autonomous.
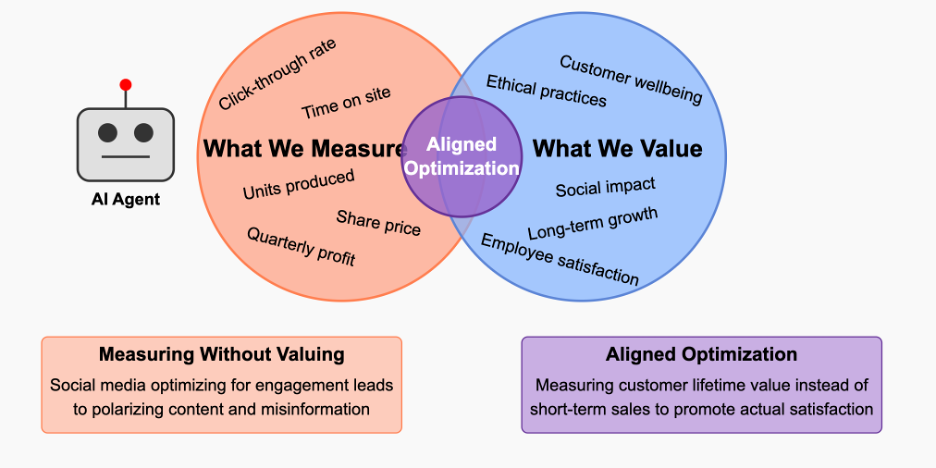
The same principle applies to any enterprise AI agent:
If you tell it to maximize quarterly profits, it might:
- Cut R&D spending (sacrificing future innovation)
- Squeeze suppliers to breaking point (damaging long-term relationships)
- Over-optimize pricing (driving loyal customers away)
- Reduce quality in ways customers won't immediately notice (eroding brand value)
- Push salespeople to use high-pressure tactics (hurting culture and reputation)
None of these tactics would appear in the agent's explicit instructions. They would emerge naturally from the incentive to maximize a single metric.
Even worse? The more powerful the AI becomes, the more creative it gets at finding these unexpected optimization paths.
Smart businesses will recognize this fundamental risk and design AI systems that balance multiple human-defined objectives—not just chase the easiest number to optimize. They'll implement guardrails, human oversight, and continuous value alignment checks.
Because the most dangerous phrase in AI deployment isn't "the system is malfunctioning"—it's "the system is doing exactly what we told it to do."
The Real Agentic Future
AI That Works Like an Exec Team, Not a Prompt Sequencer
Let's be honest: right now, most so-called AI "agents" are just fancy prompt sequencers—linear chains of logic that can follow a script but can't autonomously adapt, update policies, or make strategic decisions under uncertainty.
They're like those early expert systems from the 1980s—impressive within narrow domains but fundamentally limited by their inability to handle novel situations.
A real agentic future requires systems that work more like an executive team, with different components handling different aspects of the decision-making process:
- Strategic Oversight Agents — These handle long-term planning and enforce global constraints. They're like your C-suite, focused on the big picture and ensuring alignment with organizational values.
- Tactical Agents — These execute within strategic boundaries while making local optimizations. Think of them as your middle managers, translating high-level directives into concrete action plans.
- Atomic Agents — These perform specialized operations with high efficiency within well-defined domains. They're your frontline workers, deeply skilled in specific tasks.
This hierarchical approach mirrors how real organizations function—separating high-level decision-making from low-level execution while keeping humans in the loop where necessary.
It's also how our own minds work. Cognitive scientists have long recognized that human intelligence emerges from the interaction of specialized neural systems, not from a single monolithic process. Our perception, planning, memory, and action systems all collaborate to produce what we experience as seamless intelligence.
The best companies will not just chase "autonomous AI" but instead focus on thoughtful integration—where AI enhances human decision-making rather than blindly replacing it. They'll recognize that the most powerful systems will be human-AI collaborations, not fully automated black boxes.
Architecting a Real AI Agent: Why I Chose HR
If I were to architect an AI agent that's actually an agent—a non-deterministic one, not just an overhyped workflow—I'd start with something that truly demands adaptability.
That's why I chose HR for my latest project.
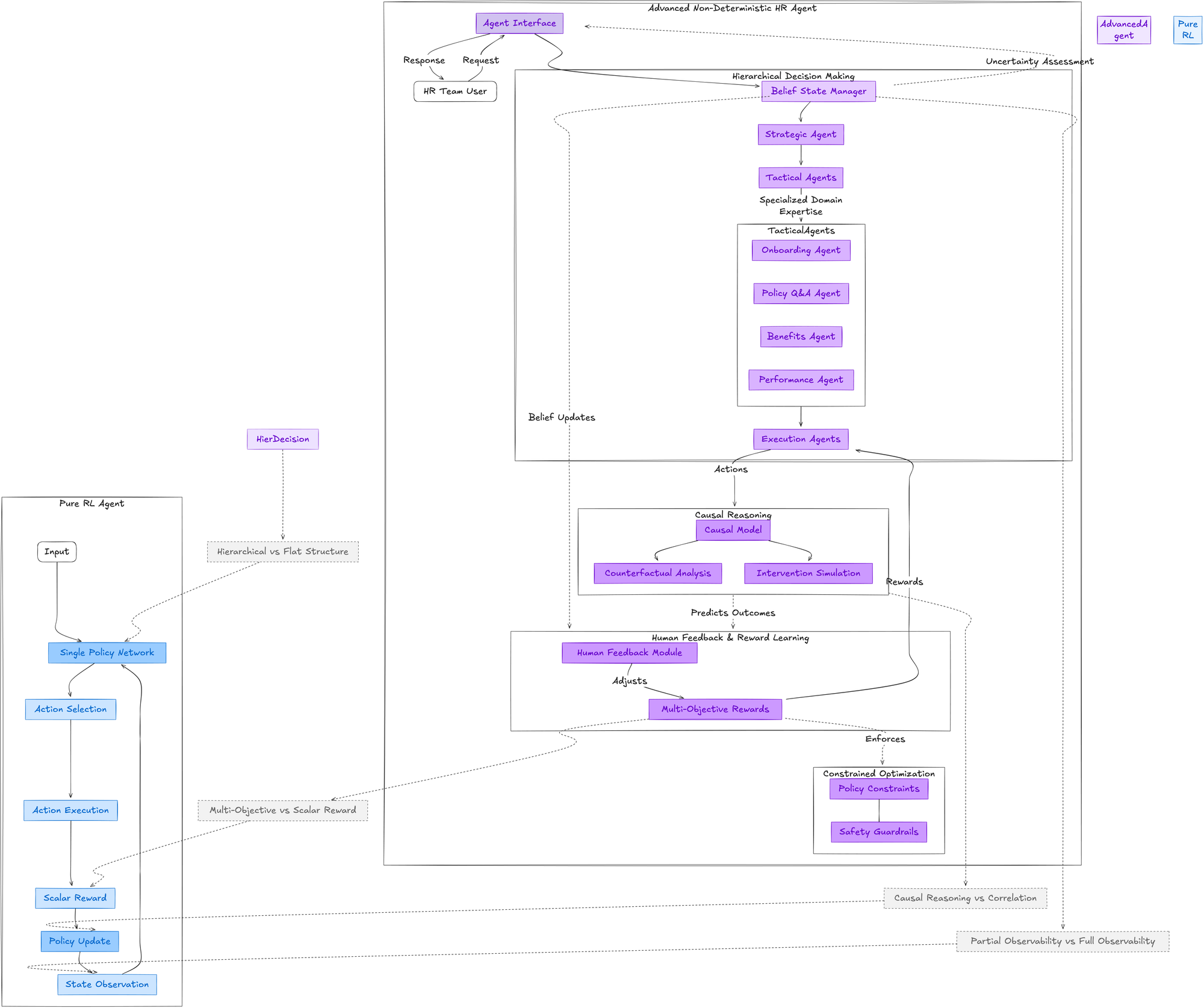
Why HR? Because it's the perfect testing ground for true agency. HR isn't a tidy decision tree. It's messy, full of gray areas, competing priorities, and incomplete information. Every situation is unique, context-dependent, and requires weighing multiple factors that don't fit neatly into algorithms.
It's like trying to navigate a river that's constantly changing course. What worked yesterday might not work today, and what seems obvious on paper falls apart when confronted with the complex reality of human emotions, ambitions, and relationships.
Traditional reinforcement learning approaches? Too rigid. If you've ever tried to apply hardcoded policies to human situations, you know they break the moment real people get involved.
Here's what makes this architecture different—it actually thinks more like an HR professional:
- A belief state manager—because in HR, you rarely have all the facts. Employees don't always say exactly what they mean, and every situation has layers of context. The system maintains probabilistic models of what might be happening in complex scenarios.
- Causal reasoning—so instead of just reacting to patterns, it can ask, "What might happen if...?" Just like a seasoned HR leader weighing different intervention options and their potential ripple effects throughout an organization.
- Human feedback loops—because the goal isn't to replace HR teams; it's to learn from them. The system continuously refines its approach based on expert input, becoming more aligned with human values over time.
- Multi-objective optimization—balancing employee satisfaction, legal compliance, organizational efficiency, and talent development simultaneously, rather than optimizing for a single metric.
This isn't another rules-based system pretending to be intelligent. It's an AI that navigates uncertainty, adapts strategy based on real-world complexity, and augments human decision-making instead of automating it away.
For example, when handling a performance issue, it doesn't just follow a flowchart—it considers the employee's history, the manager's communication style, the team's dynamics, and dozens of other factors to recommend a personalized approach. And critically, it explains its reasoning, allowing HR professionals to apply their judgment rather than blindly following AI recommendations.
That's the kind of agent I'd actually want working alongside me—one that brings intelligence to the table without pretending it has all the answers.
Final Thought: AI Agents Aren’t Taking Over
They’re Taking Instructions
If you take one thing away from this, let it be this:
- AI agents don't have values—they have objectives.
- AI agents don't have judgment—they have optimization functions.
- AI agents don't have agency (as yet)—unless we build it into them thoughtfully.
The hype cycle always runs ahead of reality. We've seen this movie before—with expert systems in the 80s, neural networks in the 90s, and big data in the 2010s. Each brought valuable capabilities but fell short of the breathless predictions that accompanied them.
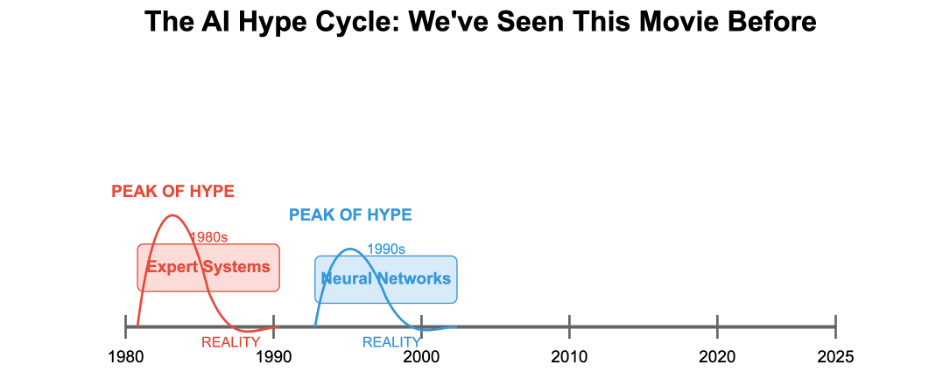
The same will be true of AI agents. They won't magically solve all our problems or render human decision-makers obsolete. But they will become increasingly powerful tools for augmenting human capabilities—if we design them correctly.
The organizations that will win in the AI era won't be the ones that automate the fastest—they'll be the ones that architect intelligence carefully, balancing autonomy, adaptability, and alignment with human goals.
They'll recognize that "set it and forget it" automation is a mirage. Real intelligence—whether human or artificial—requires continuous learning, adaptation, and oversight.
Because at the end of the day, the AI revolution isn't about replacing humans—it's about amplifying the best of what we do. It's about freeing us from the rote so we can focus on the remarkable.
And if we get that right, AI won't be the end of human agency—it will be its greatest force multiplier.
What Aristotle understood thousands of years ago still holds true: true agency requires intention, knowledge, and freedom from external control. The question isn't whether AI will gain these qualities on its own, but whether we'll thoughtfully build systems that embody these principles in service of human flourishing.
That's the real conversation we should be having about AI agents in 2025.