DeepSeek, Mixture of Experts, and the Future of Agentic AI

If you’ve been following AI’s whirlwind evolution, you’ve probably heard the buzz about DeepSeek R1 last week. It’s being hailed as the new king of large language models, the one everyone’s talking about—for now, at least. Naturally, I had to spend my weekend testing it out. And I’m not ashamed to admit it: I fell for it.
At first, DeepSeek felt like just another fancy name in the crowded world of LLMs. But the more I explored, the clearer it became—this wasn’t just another LLM. It’s efficient, clever, and built like a Swiss Army knife. It delivers results without needing a supercomputer to keep it running, which, frankly, is a bit miraculous.
What really grabbed me, though, was the architecture. DeepSeek R1 isn’t just efficient—it’s smart engineering in action. It does things differently with techniques like Mixture of Experts (MoE), FP8 precision, Multi-Level Head Attention (MLHA) and something called Direct Preference Optimization (DPO). I know, I know—buzzwords. But these are more than that. They’re design choices that hint at what the future of AI might look like.
How Large Language Models Actually Work
"Before mastering the art of perfect seasoning, you first need to learn how to make the stew." - Unknown
Before we get into what makes DeepSeek different, let’s briefly explore how large language models (LLMs) like Claude-Sonnet, GPT-4 or DeepSeek-R1 work under the hood. Think of an LLM as a giant brain designed for prediction: given some input, it predicts the most likely next token (word, subword, or character).
There are two parts to this process:
Part 1: Self-Attention: The Brain’s Focus Mechanism
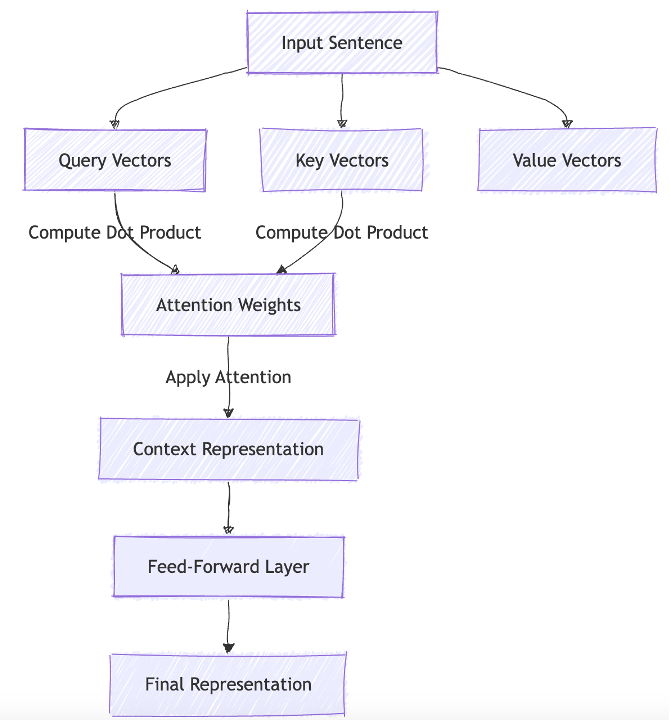
At the heart of an LLM is the transformer architecture, which uses a mechanism called self-attention to determine which parts of an input sequence matter most. For example:
- Sentence: “The tiger, which was hungry, chased the deer.”
- Self-attention ensures that “chased” pays more attention to “tiger” than “hungry,” capturing the grammatical structure.
Technically, this is achieved by creating Query (Q), Key (K), and Value (V) vectors - Oh, I know geek speak again…let me try differently.
Imagine you're organizing a big Indian wedding and need to figure out who should talk to whom to ensure everything runs smoothly. Here’s how Query (Q), Key (K), and Value (V) come into play:
- Query (Q): Each guest asks, “Who here can help me with what I need?”
- For example, the bride’s mother might ask, “Who’s handling the flowers?” or “Who knows about the caterer?”
- Key (K): Each helper (guest) shares their role or skill:
- The florist says, “I’m the flower person,” while the caterer says, “I’m managing the food.”
- Value (V): Once the right match is found, they share the information or help needed:
- The florist provides details about the delivery timing, and the caterer explains the food menu.
How it Works Technically:
- The bride’s mother (Query) compares her need (“flowers”) to the skills of everyone present (Keys).
- If the Query and Key match (e.g., the florist), it’s considered relevant.
- The model then assigns priority based on the best match using a system like softmax normalization.
- In this case, the florist gets the most attention for flower-related questions, while the caterer is ignored for this task.
- Finally, the florist shares their Value, like the delivery time or flower types.
In the sentence:
- Query asks the question: Who do I need?
- Key provides the answer: What skills do I have?
- Value provides the details: Here’s how I can help.
By using this approach, the model ensures that every word in a sentence (or guest at the wedding) connects with the most relevant part, much like a well-coordinated Indian wedding where everything comes together seamlessly!
Part 2: Feed-Forward Layers: Refining the Output
Once the bride’s mother has figured out who she needs to talk to (thanks to Query, Key, and Value matching), the conversation doesn’t end there. The information from these interactions needs to be refined, layered, and translated into actionable plans. That’s where the Feed-Forward Layers come in—think of them as wedding planners.
How Feed-Forward Layers Work in the Wedding Context:
- Information Gathering:
- After talking to the florist, the bride’s mother learns the flower delivery time and types of flowers available.
- Similarly, she talks to the caterer and learns about food options.
- Refinement and Decision-Making:
- The wedding planners (Feed-Forward Layers) take all this raw information—flower types, delivery timings, menu choices—and process it further to finalize decisions.
- For example, they might decide:
- Use marigolds for the mandap and roses for the dining area.
- Serve a mix of North Indian and South Indian cuisines to keep guests happy.
- Adding Depth and Abstract Patterns:
- The planners don’t just pass along information as-is. They combine details into a cohesive vision:
- “Let’s match the flower decorations to the bride’s outfit.”
- “Let’s serve mango lassi during the summer sangeet.”
- These layers add creativity and nuance, transforming simple facts into meaningful, actionable decisions.
- The planners don’t just pass along information as-is. They combine details into a cohesive vision:
In an LLM, once the self-attention mechanism figures out which words (or concepts) are important, Feed-Forward Layers take over to:
- Refine and combine the relationships identified in the attention step.
- Add non-linear transformations (like layering abstract ideas) to connect higher-level concepts.
- For example:
- Raw input: “tiger” and “deer” are related through “chased.”
- Feed-Forward Output: “The tiger is the predator, and the deer is the prey.”
- For example:
Why Feed-Forward Layers Matter:
Just as a good wedding planner turns raw conversations into a perfect event plan, Feed-Forward Layers take the attention-calculated relationships and build abstract understanding that lets the model answer complex questions, complete sentences, or even create poetic responses.
What DeepSeek Got Right (based on what I could glean…)
"Necessity may be the mother of invention, but scarcity is its greatest teacher." - Unknown
Now that we understand how LLMs focus attention (like a well-coordinated wedding planner) and refine information (like distilling ideas into actionable plans), there’s one lingering problem: inefficiency. Imagine if the musicians in the wedding band, responsible for the dhol (drums) and baraat (marriage procession) music, were also asked to move the heavy mandap chairs or carry crates of food. Sure, the job would get done, but at what cost? The band might lose its rhythm, the baraat would fall flat, and the guests might have a less-than-magical experience.
This is the problem with traditional models. They activate all their parameters for every task, no matter how irrelevant or resource-intensive. This one-size-fits-all approach is computationally expensive, wastes energy, and limits scalability.
This is where DeepSeek stands apart. Instead of treating the foundational mechanisms like self-attention and feed-forward layers as static, DeepSeek re-engineered their execution.
...But How Did They Actually Do It?
"True mastery is found not in broad strokes, but in the precision of the smallest details." - Unknown
Deepseek appears to have applied a range of techniques to optimize operations, enabling them to run so frugally. Some of these techniques include:
Direct Preference Optimization (DPO): An RLHF Alternative
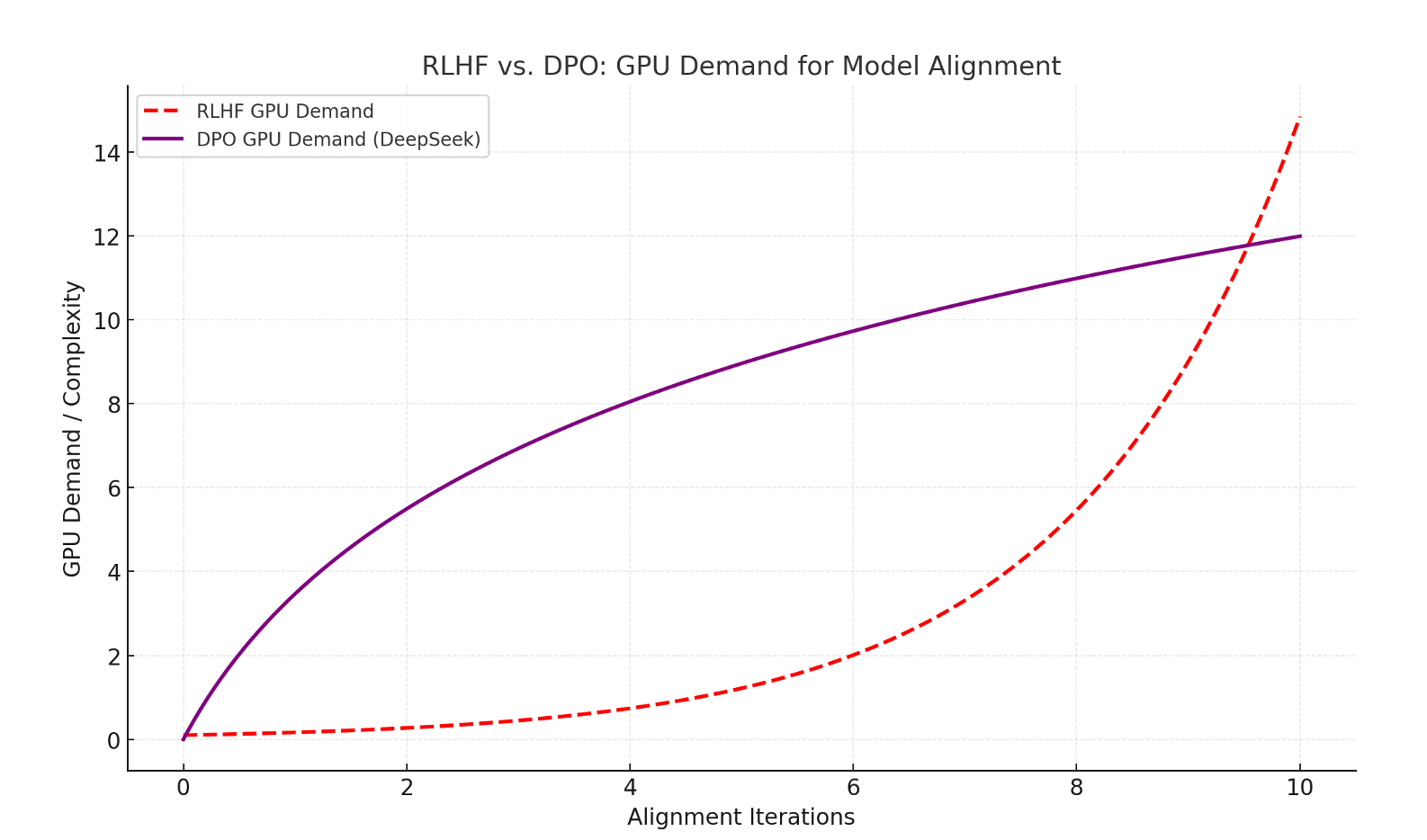
Most advanced LLMs, like ChatGPT, use Reinforcement Learning with Human Feedback (RLHF) to align outputs with user preferences - that's a kind of gold standard.
While powerful, RLHF is notoriously complex and resource-intensive. Going back to our Indian wedding metaphor, RLHF is like the planner creating a detailed reward model to predict which choices would make the families happiest. This involves running several simulations (mock weddings) to test which combinations of decisions—decor themes, food menus, or rituals—get the highest satisfaction scores. Afterward, the planner uses these simulated scores to fine-tune the plan over several iterations. While effective, this process is highly resource-intensive and requires a lot of infrastructure, from data collection to constant recalibration, to ensure every choice aligns with everyone’s preferences.
DeepSeek took a different approach with Direct Preference Optimization (DPO):
- Instead of simulating reinforcement learning, they fine-tuned the model directly on preference-labeled data in a supervised manner. In our Indian wedding metaphor, DPO skips the simulations and mock events. Instead, the planner directly gathers preference-labeled data—feedback from families about what they want (and don’t want) through a few focused conversations.
- This approach simplifies the alignment process while achieving comparable results to RLHF.
Why this matters:
- DPO eliminates much of the infrastructure complexity associated with RLHF, making alignment more accessible to teams with limited resources.
- It aligns the model more directly with user preferences, reducing the risk of instability during fine-tuning.
FP8 Precision: Lightweight, Fast, and Efficient
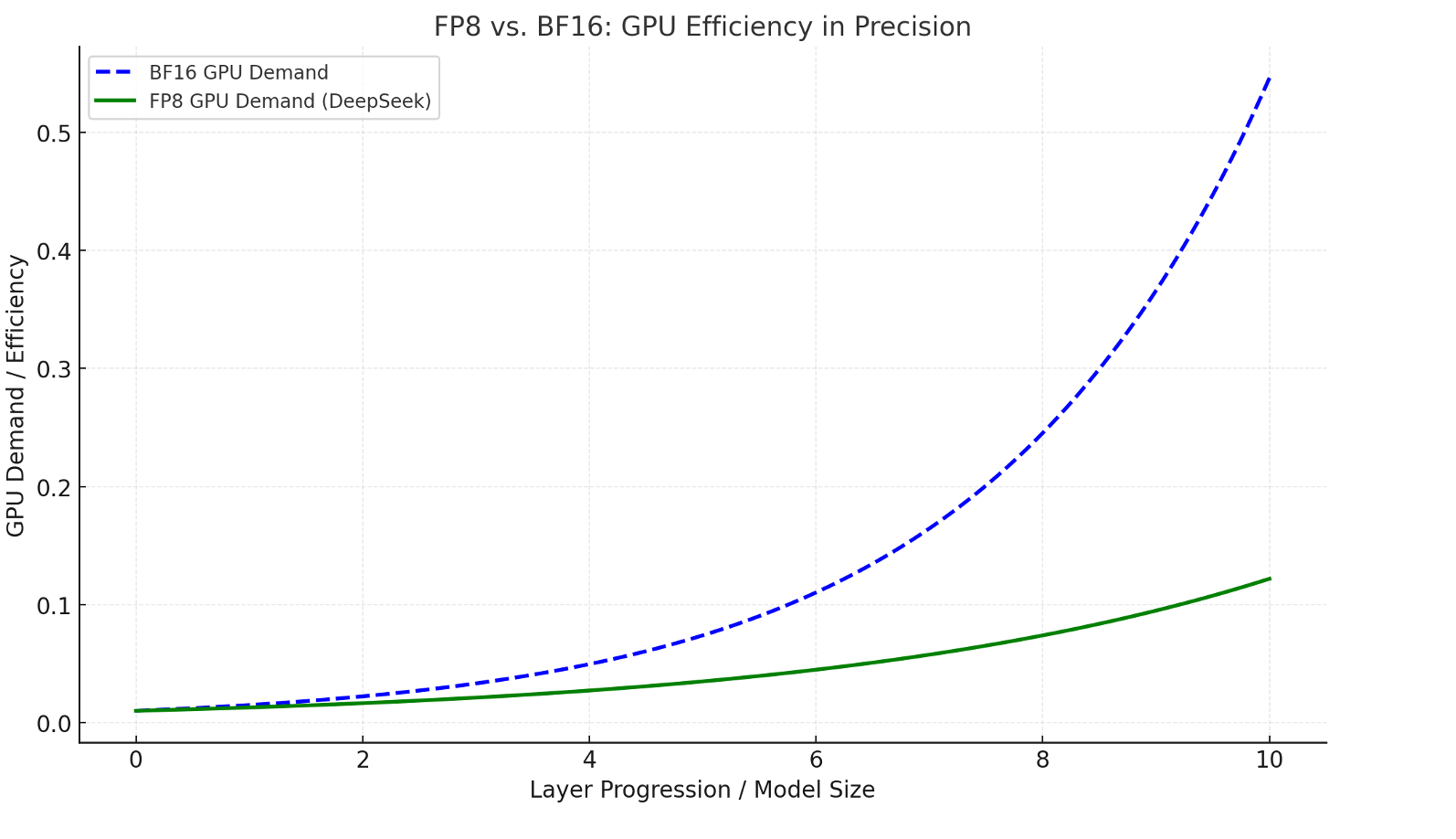
The other first we saw in DeepSeek is that traditional LLMs usually work with high-precision numbers like FP32, which is like writing down every tiny detail, say 1.23456789. Lower precision, like FP16, simplifies this to 1.2345, and FP8 takes it even further to 1.23. Sounds great for saving space and time, right?
But here’s the catch—just like a wedding, there are parts where “simpler” works and others where it doesn’t.
For things like stage decorations, you can simplify—"just some flowers and lights" (FP8). But for the food? You want precision—no one’s forgiving you for undercooked biryani or watery dal! Similarly, DeepSeek didn’t use FP8 everywhere. They carefully picked where to use it and where not to.
How They Pulled Off the FP8 Magic:
- Selective Simplification:
DeepSeek used FP8 for the parts of the model where rough estimates wouldn’t hurt, like general matrix multiplications. For critical computations—like stabilization layers or normalization—they stuck to FP16 or FP32 to ensure nothing went wrong. - Advanced Stabilization:
Training with FP8 is tricky—it can get unstable quickly. DeepSeek introduced stabilization techniques like dynamic scaling to keep things running smoothly, much like balancing a wedding budget so no one notices the frugal choices.
Why It Works:
- Massive Savings:
FP8 reduces memory usage and computation time by a huge margin, letting DeepSeek run their training on commodity GPUs without losing much accuracy. - No Compromises on Quality:
By switching back to higher precision for critical tasks, they ensured the final model performed like a luxury wedding, even if parts of the plan were streamlined.
Multi-Level Head Attention (MLHA): The Art of Layered Understanding
DeepSeek took a fresh approach to one of the most critical aspects of large language models—attention mechanisms. They introduced Multi-Level Head Attention (MLHA), an extension of the standard multi-head attention system. Think of it as not just looking at a conversation word-by-word but understanding the broader storyline by aggregating insights across all chapters.
Going back to wedding planning metaphor; imagine that inputs are coming from almost everyone—parents discussing rituals (local context), siblings debating the theme (sentence-level), and relatives weighing in on seating charts (paragraph-level). A regular planner might treat all feedback equally at face value. But a great planner like DeepSeek’s MLHA steps back to see the full picture, synthesizing these inputs into a cohesive plan where everything fits beautifully together.
How MLHA Works Its Magic:
- Hierarchical Context Building:
Traditional multi-head attention captures relationships within a single layer, focusing on what’s happening locally (like understanding one family member’s preferences). MLHA goes further by aggregating attention outputs across layers, creating a hierarchical understanding of both local (word-to-word) and global (sentence-to-paragraph) relationships. - Efficient Insights:
MLHA doesn’t just repeat work at every level; it cleverly leverages prior computations. It’s like keeping notes from earlier discussions and building on them, reducing redundancy and avoiding repetitive planning.
Thus, by integrating attention outputs across multiple levels, MLHA provides a richer, layered understanding of input sequences. This helps the model grasp the subtle interplay between words, sentences, and overarching themes—essential for nuanced responses.
...Btw, you might ask, great, that’s better, but how does it make it cheaper or more cost-efficient?Think of a tiger chasing a deer. Regular multi-head attention notices everything—the deer’s direction, the trees, the boulder, even the grass. MLHA is smarter: at the first layer, it only notes "deer running" and zooms in on details like zigzags or terrain at deeper layers if needed. This dynamic focus avoids wasting computation on unnecessary details, making it GPU-efficient and cost-effective while still keeping the big picture intact. Neat, right? So, the key insight here is that regular multi-head attention is both expensive and suboptimal because it burns through computational power without fully leveraging context from multiple layers, making it a double hit.
Mixture of Experts (MoE): Smarter Specialization for Efficiency
This one is most fascinating to me personally and perhaps the reason I wanted to write this essay. To me, DeepSeek asked a clever question here:
"Why make the entire wedding band play every song when you can hire specialists for each moment?"
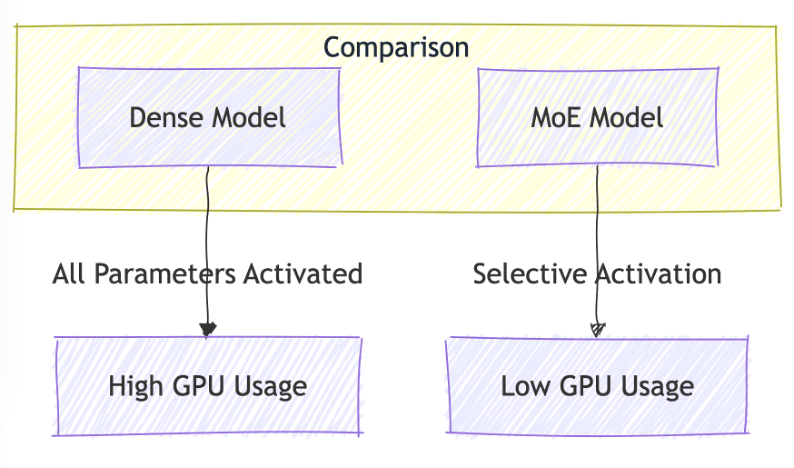
Most large language models (LLMs) activate all parameters for every input, like keeping every light in a wedding venue on, even if only one room is in use. Mixture of Experts (MoE) takes a smarter approach by activating only a subset of experts for each input. These "experts" specialize in specific tasks, and a gating mechanism determines which ones to call upon, ensuring the workload is distributed efficiently.
What DeepSeek Did Differently:
- Optimized Gating Mechanism:
While standard MoE systems sometimes overwork a few experts and neglect others, DeepSeek refined the gating mechanism to balance workloads. This ensured that tasks were distributed evenly, preventing bottlenecks and keeping all experts productive—like assigning the DJ for upbeat moments, the classical band for rituals, and the soloist for the first dance. - Targeted Fine-Tuning for Depth:
DeepSeek didn’t stop at distributing tasks; they fine-tuned each expert to become a master of its domain. This is akin to training a caterer to perfect the desserts or a florist to specialize in creating breathtaking mandaps, ensuring excellence in every area.
Why It Matters:
- Efficiency Without Waste:
By activating only the relevant experts, MoE dramatically reduces computational load, like dimming the lights in unused wedding halls. This lets the model scale effectively without unnecessary energy or resource expenditure. - Deeper Specialization:
With targeted fine-tuning, each expert brings a rich, domain-specific understanding, enabling the model to handle diverse tasks with precision. Think of it as having not just a wedding planner but a whole team of specialists for every aspect of the event.
I must note here that while this essay is inspired by DeepSeek’s novel advancements—particularly their focus on sparse architectures like Mixture of Experts (MoE) to optimize resource constraints—I would be remiss not to acknowledge the progress made by dense architectures as well. For example, LLaMA 3.3 has demonstrated the power of dense models with innovations like flash attention, which improves long-context handling by computing attention scores on the fly. This approach saves memory and compute without sacrificing performance.
These parallel advancements suggest an exciting possibility: a future where sparse and dense strategies don’t compete but converge, combining the best of both worlds to redefine efficiency and performance in large-scale models.
The Big Picture:
DeepSeek’s MoE implementation is a lesson in focused efficiency. By letting specialists handle what they’re best at and ensuring no one is overworked, they’ve created a system as elegant and well-balanced as a perfectly orchestrated wedding.
The Future: Agents as Specialized Models?
"Inspiration rarely stays within its lane—Ford found it in a slaughterhouse, and the world drove forward." - Unknown
Now that we’ve explored the impressive advancements in DeepSeek’s architecture, let’s shift gears and dive into something even more thought-provoking. Indulge me as I go out on a limb: the undeniable parallel between Mixture of Experts (MoE) and the fundamental concept of AI agents.
This was my “aha” moment: MoE and Agentic architectures share the same conceptual DNA.While these concepts operate at different levels, they share a similar divide-and-conquer approach, where specialized components (experts or agents) handle specific tasks.
MoE vs. Agents: A Shared Core
Think of MoE as a team of specialists within a large model:
- Each expert is trained for a specific task or input type (e.g., language understanding, sentiment analysis).
- A gating mechanism decides which experts are activated, based on the task.
- Only the necessary experts are used, saving computational resources and avoiding complexity.
Now, think of AI agents as they exist today:
- Each “agent” is like a specialized program or API, designed for a specific task (e.g., summarization, coding, or an API call).
- A central controller orchestrates the process, deciding which agent to activate based on the user’s query.
- Agents work externally, as modular systems that bring versatility to AI applications.
The big question:
Could agents themselves evolve into task-specific models, mirroring the specialization seen in MoE systems?
A Vision for Agentic AI
Imagine a future where agents are no longer passive, static orchestrators. I could be totally wrong, but, I think we’ve become too entrenched in an application development mindset—focused on APIs and microservices. Don’t get me wrong, I’ve been an application and data engineering guy in martech my entire career, and I love it—but maybe we’re missing the forest for the trees.
This isn’t just about building smarter CRUD API calls; we’re on the brink of an intelligence revolution. What if these agents became intelligent collaborators—mini models or experts—designed for precision and efficiency? Here’s what that could look like:
- Specialized Mini-LLMs:
Agents would evolve into lightweight, task-specific models fine-tuned for domains like summarization, data analysis, or coding. Think of them as mini-LLMs, designed for razor-sharp accuracy in their niches. - Dynamic Collaboration:
A gating mechanism could activate only the agents relevant to a specific query—just as MoE activates experts inside a large model. - Local Execution:
These agents could run on edge devices like phones, smartwatches, or home assistants. This would reduce dependence on cloud-based infrastructure and enable real-time, personalized AI experiences.
The Bridge: Distillation from Large Models to Agents
How do we build this future? Distillation.
Large models like GPT or DeepSeek could act as teachers, transferring their broad knowledge to smaller, specialized agents. Over time, these agents would:
- Learn Deeply: Absorb task-specific expertise, improving their precision with specialized data.
- Surpass Their Teachers: In their domains, these agents could eventually outperform the large models that trained them.
- Collaborate Intelligently: Work together as a network of specialized systems, creating smarter, more efficient AI ecosystems.
It’s like a university system: large models serve as professors, training agents to become domain experts who eventually excel beyond their mentors in specific fields.
The Implications: A Smarter, Modular AI Future
If agents evolve as specialized, task-oriented models, here’s what the future holds:
- Efficiency:
Activating only the necessary agents drastically cuts computational costs, much like turning off the lights in unused rooms. - Scalability:
Adding capabilities becomes modular. Instead of retraining an enormous model, you simply add a new agent. - Personalization:
Lightweight agents could adapt to individuals or organizations, creating hyper-personalized AI experiences.
Why This Future Feels Inevitable
At some point, the compute race must yield to smarter design. Centralized, dense models can’t scale indefinitely, but a modular ecosystem of lightweight, specialized agents? That’s efficient, adaptable, and sustainable.
It’s no longer a question of if this will happen—only when. So, the next time you think about agents, don’t stop at static orchestrators of today. Envision a world where specialized task models run seamlessly on your devices, making AI faster, smarter, and more accessible than ever before.
The future of AI isn’t a single monolithic brain; it’s an intelligent network of collaborators. And it’s closer than you think.